Bayesian Rose Trees のメモ
まぁ,とにかく 開いたら

が,目に飛び込んでくる Rose Treesの論文です.
1st author は Blundell さんですが, 2nd がノンパラベイズで大量に良い論文をかいておられる Yee Whye Tehさん
で 3rd が Heller さん.僕のなかでは IHHMM の論文が有名(無限階層の階層HMM ノンパラベイズ).
Rose Tree とか僕はしらないので, 「なんやそれ」と興味をひかれていたが,放置していました.
Teh さんが HPでrecommend していたので,面白いのだろうと思っていた.
要は 階層クラスタリングでベイズ的にやりたいのですが,既存のものは Binary tree (二分木)が多いので
一気に複数にわかれる事のできる階層クラスタリングを作りましょう.という話です.
K. A. Heller and Z. Ghahramani. Bayesian Hierarchical
Clustering. In ICML, volume 21, 2005.
の拡張になっている模様.
Tehさんがスライドまでオープンにしてくれていて分かりやすかった.
http://www.gatsby.ucl.ac.uk/~ywteh/research/npbayes/brt.pdf
ありがたい!
階層的分類を考える場合には 階層的な分割Partition の生成であり,その再帰的な定義が必要になる.
![]()
このあたりが,そう.
スライドの方で,分かりやすく書いてくれているので,わかると思う.
で,その確率をどう与えるかというと,
ここが 僕的には面白いポイントだとおもうんですが,
各階層のPartitionの混合 mixture として,あたえるんですね.
![]()
数式的にはこれ.
We interpret a rose tree T as a mixture over partitions
in P(T) of the data points at its leaves D = leaves(T):
さらっと書いてあるけど,僕的にはこれがキモ.
次式もややこしそうだけど,ただの展開.
あとは,木の分かれ方で,混合率を与える.
で,推定はサンプリングで・・・・ といくのかとおもいきや,
それはcomplexity が高すぎて 無理とのことでGreedy 探索をします.

これが,Greedy 探索のための mergeの方法
ざくっというと
これらを適用してみて,尤度比が一番あがるやつを,適用していく
って感じみたい(だいたいの感じ)
Figure. 7 で GP mixture の話とかでてきてるけど,これはおまけ程度におもっておけばいい.
とにもかくにも,多分岐のツリーが作れるようになってバンザイ ということのようである.
ちなみに,先日書いた Pitman-Yor diffusion tree は,実数空間を前提にしたモデルだし,
それに比べると,空間や分布についての柔軟性はある.
# PYDT は面白いし好きなんですが.
Tree 関連 ノンパラ論文を nested CRP, PYDT, Rose Tree と読んでみたわけだが,
個人的には,Tree というものの 捉え方が まったくそれぞれ異なっていて,そのあたりが面白かった.
 たにちゅー・谷口忠大・tanichu
たにちゅー・谷口忠大・tanichu Bayesian Rose Trees だいたい分かった. Greedy search になってしまってるのが,Bayesian なわりに,悲しい感じもするが,パフォーマンスも良いようなのでいいのであろう.Tree を Partition のmixture と捉えるのおもしろい.
12:59 AM - 3 May 12 via TweetDeck · Details
"BRT and one version of BHC interpret trees as mixtures over partitions." これ,ポイントやな. > Bayesian Rose Trees
12:20 AM - 3 May 12 via TweetDeck · Details
なるほど, サーチは greedy サーチになっちゃうのか. hyperparameter は勾配でもとめるのか. 適宜そういう選択もするとっころはだいじやな.http://bit.ly/ITBWUK
12:17 AM - 3 May 12 via TweetDeck · Details
スライドを見て, A tree is treated as a mixture of partitions. の意味がちょっとわかった.... nested CRP に引き続き,tree を確率モデルとしてどう扱うか という事は なかなか 面白いところみたいな気がする.
12:00 AM - 3 May 12 via TweetDeck · Details
Bayesian Rose Trees の発表スライド http://bit.ly/ITBWUK







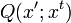


![ビブリオバトル[知的書評合戦]](img/bn_biblio.jpg)
