The Infinite Partially Observable Markov Decision Process のメモ
これまたTehさんの
Modern Bayesian Nonparametrics.
http://www.gatsby.ucl.ac.uk/~ywteh/teaching/npbayes.html
の影響で読んでみた.
The Infinite Partially Observable Markov Decision Process
F Doshi-Velez
NIPS2009 http://nips.cc/Conferences/2009/Program/event.php?ID=1643
ですね.
POMDPは 強化学習でよく仮定する MDPと違い,状態s_t が直接観測できないという仮定のもの.
歴史的にPOMDPと呼ばれるが,個人的にはHidden MDPとでも呼んでみたい気がしますが,
まぁ,そういうものです.
銅谷先生らのモジュール型強化学習などをイジっていた身としては,
Dirichlet Process mixture が出てきた段階から,まぁ,連続状態変数を隠れ状態からの出力分布でとらえて
その上で強化学習とかしたいよね.とか思っていたわけなんですが,
まぁ,そんな感じのモデルです.
まだ,Theoreticalな部分先行で実ロボットでどうこうという話ではない.
内容は基本的部分はシンプルで,
DPで隠れ状態 s_t が生成されると,
それらが,iHMMよろしくで, s,a の条件の下で DPから生成された多項分布(つまりは,遷移確率行列)で次の状態にトランジションする.
また,観測o ,報酬 r がそれぞれの s,a に対しての分布として生成されますよという生成過程

とってもagree な内容となっております.
で,このあたりはいいのですが,
やっぱり,ただでさえ,学習に時間がかかったりする強化学習さらにPOMDP.
Action Selectionの方が大変になっています.
実際には,belief を求めるのも, 複数のモデルをサンプルしてその上での信念分布を考えて
これの重ねあわせで考える. Q値も同様に考えるといった,近似を導入しています.
このあたりは,個人的には苦しそうな印象.
また,最適政策も求めにくいので,
Given a set of models, we apply a stochastic forward search in the model-space to choose an action.
The general idea behind forward search [14] is to use a forward-looking tree to compute the value
of each action.
ということで,フォワード探索で頑張って決めていきます.
実験では,ちゃんと動くぞ,というのを示していますが,
確かに状態数の推定はいいのですが,

そこからの強化学習としての方策生成まで,うまくつなげて綺麗な理論にするのは大変やなぁと思いました.
ただ,ノンパラベイズからの強化学習へのアプローチとしては,非常に素直だとおもうので,一読の価値はあるかと.
POMDPやんなきゃ感 カンジテル・・・・
※本 メモは大いに間違っている可能性もあるので,間違いに気づかれた方は,心優しくツッコんでください.
 たにちゅー+Rやで(谷口忠大)
たにちゅー+Rやで(谷口忠大) 強化学習 Natural Actor-Critic が流行っていたあたり つまみ食いした以降は ちょっとサボっていました. 現状は どうなっているんでしょうね.
8:51 PM - 18 Apr 12 via TweetDeck · Details
POMDPとSLAMの関係について.
8:49 PM - 18 Apr 12 via TweetDeck · Details
しかしまあ,どんだけ tractable になっているかって話ですね. 不確実性のある実空間で行動意思決定するとなったら,教師なしのモデリングつかった 認識の話だけでなく やっぱ,強化学習は入れたくなるのが人情.ノンパラベイズ強化学習はやってる人はそんなにおおくないのかな.
8:41 PM - 18 Apr 12 via TweetDeck · Details
Partially Observable Markov Decision Process ね POMDP . 昔は確定的な ちょいヒューリスティックっぽい話がおおかった気がしたけど,こんだけベイズがしっかりしてきたら,綺麗な話になってきているのね.
8:40 PM - 18 Apr 12 via TweetDeck · Details
POMDPとか,久しぶりに読んでいる.






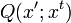
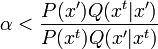


![ビブリオバトル[知的書評合戦]](img/bn_biblio.jpg)
