2007年度までの研究成果
2009-07-25 (sat)|カテゴリー:|Comments Off
以下は主に2006年度までに,京都大学工学研究科在籍時に取り組んだ研究である.
HOME > RESEARCH > 2007年度までの研究成果

工学の歴史は現代社会に物質的豊かさもたらしてきました.
結果的に,多くの先進国では市民が充分な物質的豊かさを享受し,その飽和を肌で感じるようになっています.
その一方で,人と人工物が関わり合う現場では人工物が人から切り離された状態で持ちうる価値と,人を含んだ系において人工物が持ちうる価値の間に差が生まれてきているのでは無いでしょうか?その差分こそが,人間と人工物が共生する世界における固有の価値であると言えるでしょう.
人間の排除を理想とした航空機などの自動化設計や原子力発電所の安全設計はヒューマンエラー(人的過誤)を排除できずにいます.また,知能ロボットは観 客を閉め出した劇場空間では見事に振る舞うが街中に現われることは出来ず,発売されたペットロボットは決まりきった動作を繰り返し三日で飽きられてしまう 状況です.
人工物の機能・性能は多くの場合,ユーザや環境が平均的な状態であること,理想的な状態であること,あらかじめ想定された状態であることを仮定して設計されているのではないでしょうか?
しかし,現実世界は当然のように動的で時変的であり,系の主要な構成素たる人間は環境と不断の身体的,社会的相互作用を繰り返す中で適応・学習を通じて変化していくのです.
そして,ボトムアップに形成された秩序が再びトップダウンな制約として諸要素の行動を支配することになります.これは「創発 (emergence)」や「周縁制御 (marginal control)」という言葉と関係しています.
このような系を理解し,よりユーザに高い価値をもたらす人工物や制度を生み出す為に,そのような系のモデリングを通じた
を主眼に研究を行ってきた.
人を含んだ系では何よりも,人が適応的で自律的に変化する存在である点が最も重要です.その為,
の二つの問題意識を基礎としながら各種の手法,計算知能モデルを提案してきました.
自律適応系の対象・環境概念生成の側面に注目し,自律ロボットが関わる環境・対象を表象する内的表象を自律的に構成する機械学習手法として双シェマモデルを構築し,その特性や有用性について 一連の研究を行った.
このモデルにおいて自律ロボットは,動的環境に含まれる定常状態において身体的相互作用のダイナミクスを知覚シェマとして組織化し,その変化点に自発的に気づき知覚シェマを分化させる.
シェマモデルとは発達心理学者のJ. Piagetが 幼児の認知発達を説明するために提案した認知システムのモデルであるが,我々はそれに再解釈を与え計算論的モデルとして構築した.

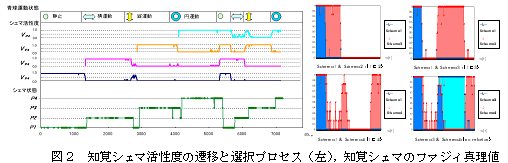
図1は実験において用い たpan-tiltの二自由度の運動系を有し,二つのカメラを感覚系に有した顔ロボットである.実験を通じて,顔ロボットは自らの自己閉鎖的な学習過程の みから外部で切り替えられる環境状況を表象する4つの内的表象を組織化した.そのプロセスを図2に示す.
また,これらの知覚シェマの活性度を,各状態のそ のシェマへの帰属度を表すファジィメンバシップ関数と解釈したところ,その4つの概念間に図2に示すようなボトムアップに生成された包含関係が成立するこ とも観察された.
また,このような自らの感覚運動器のみを通した環境認識の発生は,自らの身体性の強い影響下にある.身体性と内的表象生成の関係性という議論は,実験的に は調査し難いものの,生態学的認識論や記号論,認知言語学等の学際的分野においても非常に強い興味を持たれている.
そこで,身体パラメータと内的表象の生 成数は単純な比例関係に有るのではなく非線形な関係性を持ち,さらにその存在が行動のパフォーマンスに影響を与えているとの仮説を立て,上記の表象生成モ デルを用いた数値実験により,構成論的な方法で,その仮説を擁護する数値実験結果を得た(図3).
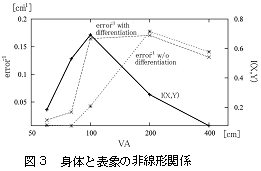
従来の実際の人間の認知実験では,踏み込めない領域を構 成論的手法で切り開いた新規性が評価され,当研究についてシステム制御情報学会より論文賞という形で評価を受けた.また,当手法の数理的側面をより厳密に すると共に,非線形系への拡張と,その他手法との比較検討を行い報告した.
人間-社会ロボットの有意味な持続的コミュニケーション実現のためにはロボット自身が相互作用を通じて行動多様性を持つ事が重要である.
私たちは上記の 対象・環境概念についての知覚シェマのみならず,行為概念である行為シェマを自律ロボットが適応的に獲得するための手法を提案した.
まず,行為シェマを強 化学習を通じて獲得する手法として双シェマモデルベースの強化学習を提案した.
獲得された行為シェマは環境変化に対して高い汎化性を示し,汎化行為概念と して作動する事が確かめられた.
次に,これを知覚シェマ同様に概念分化を通して累増的に獲得するための手法として強化学習シェマモデルを提案した.
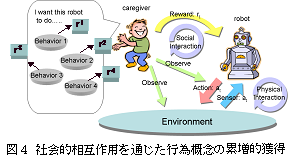
自律ロ ボットは環境との相互作用に基づく学習の中で養育者(caregiver)の設計する報酬を通して評価を受けるが,この報酬が変化したとき通常の強化学習 ではそれらを渾然一体として認識するために新たな行為で古い行為概念は上書きされてしまう.本手法により,自律ロボットはその違いに自律的に気づくことが 出来,自律ロボットが行動多様性を獲得していくことが出来るようになる(図4).
本手法は,社会ロボットが人間との自然な相互作用を通して発達する為の一 つの基盤技術となるとともに,従来の学習理論が扱ってこなかった,生物の行為多様性を獲得する記憶システムについての計算論的モデルとなっていると考えら れる.本研究について,計測自動制御学会より学術奨励賞を授与された.
関係する論文
自律ロボットが獲得した行為概念に,近年,大脳新皮質,海馬等で発見されたSTDP則と呼ばれる学習則(図6)で駆動される神経回路網を接続することで,いわゆる合図のようなインパルス型の情報と行為概念の想起を実時間的に連動させることが出来る事を示した.
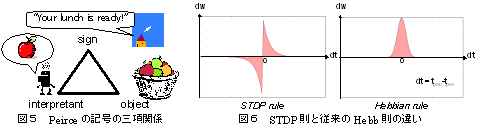
これにより,記号論の創始者C.S. Peirceが唱えた記号の構成要件である<サイン・対象・解釈項>の三項関係を有した記号解釈のプロセス(図5)を完全に自己閉鎖的な学習の中で自律ロボットにボトムアップに発見させる事が出来た.
この学習機構は強化刺激のみならず弁別刺激をも包括的に含めたオペラント条件付けの計算論モデルとして捉えられる.
本提案の力点は,外部評価的には,そのオペラント条件付けの統合的なモデル化という新規性にあるが,内部評価的には,申請者が研究を進める記号創発論, つまり,記号や意味を自律適応系の環境や他者との相互作用を通した創発性の概念の中で捉えるという,ボトムアップ・アプローチによる研究に於いて,記号の 意味解釈の組織化という概念に対して一定の計算論的位置づけを与えたという点にある.複数人のコミュニケーションや社会的な議論に発展させるための土台と なる議論である.
これらの議論を複数エージェント間のコミュニケーションの議論に発展的に進めて行くためにボトムアップな適応学 習過程を通じての他者の意図推定や,他者とのコミュニケーションの為の記号創発を議論する必要がある.
では他者の行動を直接観測できず,自らの感覚運動系 に閉じたような自律適応系が協調作業を行う他者の意図を推定し,協調的にタスクを実行するといったことが可能かという問題に接近し,モジュール型強化学習 機構を援用する事で一定の仮定の下可能であることを示した.本研究についてシステム制御情報学会より奨励賞,砂原賞を授与された.
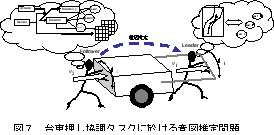
本研究では,多モードを有する自動化機械に対するユーザの学習過程およびモード認識過程を,モジュール型学習機構を用いてモデル化する事により,ヒューマンエラーの代表例の一つである人間のモード誤認識(mode error)の発生を予測出来る事を示した.
人間はモード認識を行う際には(1)モード遷移則についての知識と記憶,(2)ヒューマンインターフェイス上の表示,(3)操作上のダイナミクス(入出力関係)の三つを主な手掛りにしていると考えられるが,本研究では(3)に特に注目しモデリングを行った.
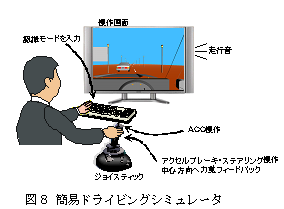
具体的には,ACC(Adaptive Auto Cruise)機能を有した自動車を実験題材にとりあげ,簡易ドライビングシミュレータ(図8)を用いた認知実験と,その結果に基づくシミュレーション実 験を行った.人間の運転履歴を記録し,これを用いて,人間の小脳周辺に獲得されるといわれる複数の状態予測器(複数内部モデル:Multiple internal models)をモデル化したモジュール型学習機構に学習とモード認識を行わせた.結果,全時間の内,約80%の時間で学習器のモード認識は人間のモード 認識に一致し,また,誤認識に限っては約50%の時間で人間と同様にモード誤認識を発生させた.これにより,複数内部モデルによるモード認識の表現の妥当 性が示された.
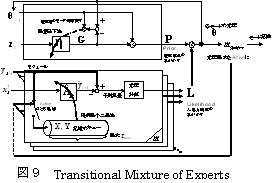
ま た,上記(1)~(3)全ての手掛りを扱う,モード認識モデルとしてTransitional Mixture of Expertsを提案した.この学習器を用いる事で,統計的学習を通じてモード遷移事象を含んだモード認識機構が学習される事は示されたが,しかし,人間 の認知実験との比較を通した検証は充分になされておらず,今後の研究を要する.
模倣学習の計算論的理解はしばしば安易に「提示された軌道の学習と再生」,つまり時系列の教師有り学習として捉えられる事があるが,実際に人間が行ってい る模倣学習には,その単純な描像では捉え切れていない問題が種々存在する.
他者の身体座標を如何に自らの身体に対応づけるかという身体部位対応問題や,相 手の行動を軌跡のレベル,目的のレベルなど如何なるレベルで模倣するのかという模倣のレベルの問題などがある.これらの問題の中で申請者等は
の二つの問題に対して研究を行った.
(a)については,模倣の結果を強化学習の初期方策として利用するのみならず,その後の強化学習で用いる副報酬の生成に利用し,模倣学習と強化学習の効率的な結合を図った.
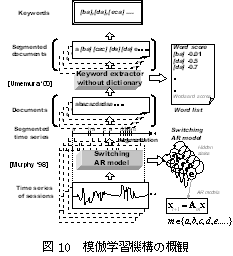
(b)については,NICT音声言語グループと協同で研究を行っている.人間の自然な動作系列をロボットが観測を続け,意味のあるセグメントを自律的に切 り出し学習する事で,プログラミングや明示的な教示といった,人間の幼児との関わり合いでは行うことのない,ユーザの特別な作業を経ることなく,ロボット が多様な振る舞いを獲得する枠組みを提案している.特徴的な点は,運動学習であるにもかかわらず,ユーザの動作系列群から意味のあるセグメントを自律的に 切り出す技術に,Webページの解析などで用いられているテキストマイニング技術のキーワード抽出技法を用いている点である.
今後はNICTが有する ヒューマノイドロボットInfanoidに当該技術を実装し,「ユーザとの自然なインタラクションから勝手に真似るロボット」の実現を目指す.当共同研究 は着任後も継続の予定である.このような人との関わり合いの中で自らの行動多様性を生み出していく適応性を有したロボットは,人間と関わり合うロボットの 市場に新たなインパクトを与えると考えられる.
人間集団,もしくは自律適応系により構成される組織においては,人間集団自らが形成するルール,記号系が構成素自らの行動を制約するミクロ・マクロループ が形成されている.近年の,脱線事故や発電所事故,消費期限偽装問題などの社会的問題は,全てヒューマンエラーでありながら,組織文化や人間関係といった 非物質的要素,つまり組織のシステム的要素に主たる問題を有している.
人間関係が負の価値を生んだこのような事例に対して,mixiのように人間集団の形 成のダイナミクスを上手く支援する事で正の価値を生み出している事例もある.しかし,現在の所,システム科学の視点から,このような創発的実体である組織 内の文化や風土形成のダイナミクスを捉え,実際のマネジメントに示唆や提案を与えうるモデルは存在しない.
また支援システムでは,携帯機器のBluetooth機能とSNSを連携させることで人間関係の形成の支援を行うシステムを,携帯電話を用いた優秀なビジ ネスプランのコンテストである,MCTPモバイルコンテンツコンテスト2006において「Social Encountering Service『街角ですれ違う友達の友達は友達』-SNSに基づくユビキタスリアルコミュニケーション-」,として提案しKLAB賞を受賞している
copyright © Tadahiro Taniguchi All Right Reserved.


![ビブリオバトル[知的書評合戦]](img/bn_biblio.jpg)
